Comment Faire Tourner OpenClaw 24/7 Sans Se Ruiner : Éliminez les Rate Limits + Réduisez les Coûts de 80%
Faire tourner OpenClaw 24/7 coûte 800-1500$/mois avec des modèles API seuls. Nous avons réduit ça à 5-10$/jour tout en éliminant les rate limits. Découvrez comment nous équilibrons l'abonnement Claude Max avec l'API Kimi K2.5 pour rendre OpenClaw abordable et fiable.


Fort de 22 ans d'expérience en IT, Roy dirige Perel Web Studio avec une passion inébranlable pour créer des solutions digitales qui génèrent de vrais résultats. La seule différence entre une bonne et une mauvaise agence web ? La passion.
En bref : Faire tourner OpenClaw 24/7 signifiait choisir entre des modèles API coûteux (800-1500$/mois) ou des rate limits frustrants. Nous avons trouvé une troisième voie : équilibrer l’abonnement Claude Max avec l’API Kimi K2.5 pour le surplus. Résultat : 5-10$/jour de coût, zéro rate limit, 80-90% d’économies. Automatisation complète via Smart Model Manager.
Mise à jour — 17 février 2026
Ce qui était écrit ci-dessus était exact au moment de la publication. Cependant, la situation a évolué de manière significative depuis lors.
Anthropic modifie continuellement ses règles de blocage et de rate limiting — notamment pour empêcher l’utilisation des tokens d’abonnement Max et Pro dans des logiciels tiers comme OpenClaw. Selon leur politique officielle, utiliser les tokens d’abonnement Claude dans des applications tierces n’est pas autorisé.
De ce fait, l’approche décrite dans cet article peut ne plus fonctionner comme décrit pour vous. Chacun doit trouver son propre équilibre en fonction de l’usage qu’il fait d’OpenClaw.
Notre approche actuelle chez Perel Web Studio (à partir de février 2026) : nous faisons désormais tourner OpenClaw sur Kimi K2.5 comme orchestrateur principal, et pour toute tâche lourde — SEO, audits, développement, ou tout autre processus consommateur de tokens — nous instruisons explicitement OpenClaw d’appeler Claude Code via bash.
Concrètement, voici ce que ça signifie : quand OpenClaw (piloté par Kimi) reçoit une tâche complexe, au lieu de la traiter directement, il exécute une commande bash qui appelle Claude Code, lequel effectue tout le travail en local. Claude Code renvoie ensuite le résultat, et Kimi/OpenClaw orchestre la sortie et répond à l’utilisateur. L’utilisateur bénéficie de toute l’intelligence de Claude pour les tâches exigeantes, tandis que Kimi gère l’orchestration légère entre les deux.
Cette configuration fonctionne parce que Claude Code opère en dehors des restrictions d’utilisation des abonnements Anthropic — il est facturé séparément via API ou fonctionne sous son propre modèle d’utilisation. Le résultat est un pipeline performant et rentable où le bon modèle prend en charge le bon travail.
Vous souhaitez mettre en place une automatisation IA de manière durable ? Découvrez nos services IA chez Perel Web Studio.
Quand votre agent OpenClaw devient subitement bête
Tout a commencé par de la confusion. Mon agent OpenClaw — celui qui fonctionnait parfaitement depuis des semaines, gérant les messages WhatsApp, automatisant les tâches, coordonnant mon équipe — a soudainement commencé à donner des réponses bizarres. Pas des erreurs. Juste… des réponses bêtes. Comme si je parlais à une IA complètement différente.
“Quel modèle es-tu ?” ai-je demandé.
La réponse était incohérente. Quelque chose sur le fait d’être utile. Aucune identification du modèle.
J’ai vérifié les logs. Aucune erreur. J’ai redémarré la passerelle. Même comportement. J’ai passé des heures à débuguer ce que je pensais être un problème de configuration, un souci de mémoire, peut-être un fichier d’état corrompu.
Puis j’ai compris : le rate limiting.
Le tueur silencieux dont personne ne vous avertit
Voici ce qui m’a surpris : quand vous atteignez les rate limits sur un plan Claude Max, vous ne recevez pas de message d’erreur. Votre agent ne plante pas. À la place, il se dégrade silencieusement. Le modèle arrête de répondre intelligemment, retombe sur des réponses génériques, ou se casse de manières subtiles et exaspérantes.
Aucune notification. Aucun avertissement. Aucun “vous avez utilisé 90% de votre quota.” Juste une bêtise soudaine.
Pour ceux d’entre nous qui font tourner des agents IA via des outils comme OpenClaw, c’est dévastateur. Vous payez un abonnement Max, vous attendez de la fiabilité, et à la place vous obtenez des pannes silencieuses qui vous font perdre des heures de débogage.
Ce que j’ai trouvé dans les logs
En fouillant dans auth-profiles.json, j’ai trouvé la preuve :
"anthropic:manual": {
"errorCount": 5,
"cooldownUntil": 1707523200000
}Cinq erreurs. Un timer de cooldown. Et zéro visibilité sur tout ça.
Les vrais chiffres derrière les rate limits Claude Max
Les plans Claude Max ont des limites strictes mal documentées :
- Fenêtre glissante de 5 heures pour les pics d’utilisation
- Plafond hebdomadaire : 15–35 heures pour Opus, 140–280 heures pour Sonnet
- Les comptes partagés multiplient le problème : 4 développeurs sur 2 comptes = rate limits constants
Quand vous faites tourner un agent IA en permanence qui gère des messages WhatsApp, Telegram et d’autres canaux, ces limites s’épuisent vite. Et vous ne le découvrez que quand votre agent commence à agir comme s’il était saoul.
Ce que nous avons essayé d’abord (et pourquoi chaque approche a échoué)
Avant d’arriver à notre solution actuelle, nous sommes passés par trois itérations. Chacune nous a appris quelque chose d’important sur la gestion des tokens OpenClaw.
Tentative 1 : Basculement réactif basé sur les erreurs
Notre première approche était simple : surveiller les erreurs Anthropic, et quand elles surviennent, basculer vers un modèle de secours.
if [[ "$ANTHROPIC_ERRORS" -ge 2 ]]; then
switch_to_fallback
fiPourquoi ça a échoué : Quand vous recevez les erreurs, le mal est déjà fait. Vos utilisateurs ont déjà eu des réponses cassées. L’agent a déjà échoué en pleine conversation. Vous avez toujours un train de retard.
Tentative 2 : Surveillance du timestamp de cooldown
Nous avons essayé de surveiller le timestamp cooldownUntil dans auth-profiles.json :
cooldown = datetime.fromtimestamp(data['cooldownUntil']/1000)
if cooldown > datetime.now():
switch_to_fallback()Pourquoi ça a échoué : Les cooldowns sont réactifs, pas prédictifs. Ils n’apparaissent qu’après que vous avez été rate limité. Même problème fondamental — réagir à l’échec au lieu de le prévenir.
Tentative 3 : Comptage de tokens
Nous avons envisagé de suivre l’utilisation réelle des tokens et d’estimer quand nous atteindrions les limites.
Pourquoi ça a échoué : Les limites Claude Max ne sont pas purement basées sur les tokens. Elles sont basées sur les patterns d’utilisation, les fenêtres glissantes et des métriques internes opaques. Le comptage de tokens ne correspond pas proprement au comportement des rate limits.
La révélation
Le retour était clair : “Le switch automatique doit éviter à tout prix un rate limiting sur Anthropic, donc on devrait construire une marge pour s’assurer de ne jamais atteindre les limitations.”
Nous devions inverser le modèle : au lieu de réagir aux limites, imposer nos propres limites plus strictes que celles d’Anthropic. Si nous budgétons 3h30 de Claude par jour et basculons avant que ce budget soit épuisé, nous n’atteindrons jamais leurs rate limits.
La solution : Gestion proactive du budget pour OpenClaw
Au lieu de réagir aux rate limits après qu’ils surviennent, nous avons construit un système proactif qui :
- Suit l’utilisation de Claude en temps réel (par temps, pas par tokens)
- Impose un budget quotidien avec une marge de sécurité de 10 minutes
- Bascule automatiquement vers Kimi K2.5 avant d’atteindre les limites
- Se réinitialise automatiquement à minuit
- Envoie des notifications WhatsApp à chaque changement de modèle
Pourquoi le suivi par temps fonctionne
Les plans Claude Max sont limités par le temps d’utilisation, pas par le nombre de tokens. Notre système suit combien de temps Claude est votre modèle actif, vous donnant des budgets quotidiens prévisibles plutôt que des erreurs de rate limit imprévisibles.
Architecture : Trois composants, zéro complexité
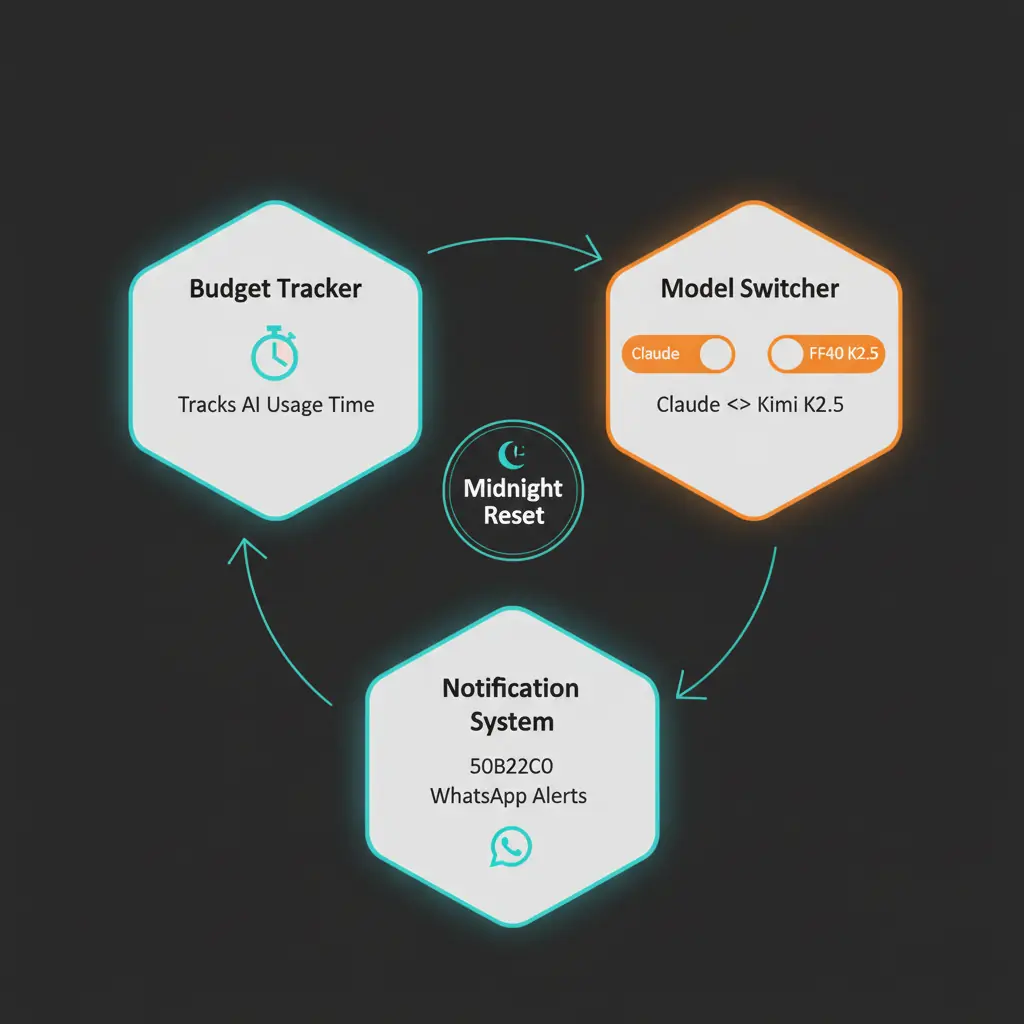
Notre Smart Model Manager se compose de trois composants qui travaillent ensemble :
┌─────────────────────────────────────────────────────────┐
│ LaunchAgent (macOS) │
│ com.perelbot.model-manager.plist │
│ Démarre au boot, reste actif │
└─────────────────────┬───────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ smart-model-manager.command │
│ │
│ - Vérifie l'utilisation toutes les 60 secondes │
│ - Suit le temps Claude dans un fichier d'état │
│ - Bascule les modèles via config OpenClaw │
│ - Envoie des notifications WhatsApp │
│ - Réinitialise le budget à minuit │
└─────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────┐
│ model-manager.command │
│ │
│ Interface de contrôle : start | stop | status | restart│
└─────────────────────────────────────────────────────────┘Implémentation : Étape par étape
1. Le fichier d’état
Nous suivons l’utilisation dans un simple fichier JSON qui persiste entre les redémarrages et se réinitialise quand la date change :
{
"date": "2026-02-12",
"claude_seconds": 7200,
"budget_exhausted": false
}2. Configuration du budget
DAILY_BUDGET_SECONDS=$((3 * 3600 + 30 * 60)) # 3h30 = 12 600 secondes
MARGIN_SECONDS=$((10 * 60)) # 10 min de marge de sécurité
EFFECTIVE_BUDGET=$((DAILY_BUDGET_SECONDS - MARGIN_SECONDS)) # 3h20La marge de sécurité de 10 minutes garantit que nous n’atteignons jamais réellement les limites d’Anthropic. Mieux vaut basculer 10 minutes trop tôt que de faire face à une erreur de rate limit en pleine conversation.
3. Logique de basculement de modèle
# Si Claude est actif et le budget pas épuisé, suivre l'utilisation
if [[ "$CURRENT_MODEL" == *"anthropic"* ]] && [[ "$BUDGET_EXHAUSTED" != "True" ]]; then
CLAUDE_SECONDS=$((CLAUDE_SECONDS + CHECK_INTERVAL))
# Vérifier si le budget est épuisé
if [[ "$CLAUDE_SECONDS" -ge "$EFFECTIVE_BUDGET" ]]; then
switch_to_kimi
fi
fi4. Notifications WhatsApp à chaque basculement
Chaque changement de modèle déclenche une notification WhatsApp pour que vous sachiez toujours ce qui se passe :
notify_whatsapp() {
local message="$1"
openclaw message send --channel whatsapp -t "$WHATSAPP_SELF" -m "$message"
}Vous recevrez des messages comme :
- “Basculé vers Kimi K2.5 (Budget Claude quotidien atteint : 3h30)”
- “Nouveau jour ! Basculé vers Claude Sonnet (budget de 3h30 disponible)“
5. Réinitialisation automatique à minuit
À minuit, le système détecte le changement de date et automatiquement :
- Remet le compteur d’utilisation à zéro
- Efface le flag
budget_exhausted - Rebascule vers Claude (si actuellement sur Kimi)
- Envoie une notification confirmant la réinitialisation
if [[ "$STATE_DATE" != "$TODAY" ]]; then
init_state
if [[ "$CURRENT_MODEL" == *"openrouter"* ]]; then
switch_to_claude
fi
fiPreuve en conditions réelles : Le tableau de bord de statut
Voici une capture d’écran réelle de notre vérification de statut WhatsApp, montrant le Smart Model Manager en production :
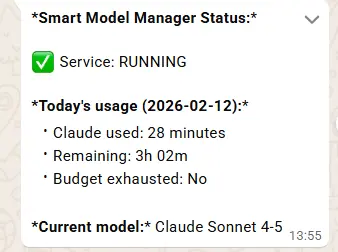
Le statut montre :
- Service : En cours d’exécution en continu
- Claude utilisé aujourd’hui : 28 minutes
- Restant : 3h 02m de budget Claude
- Budget épuisé : Non
- Modèle actuel : Claude Sonnet 4-5
C’est le genre de visibilité que nous n’avions jamais eue auparavant. Plus de devinettes, plus de surprises.
Pourquoi Kimi K2.5 est le modèle de secours parfait pour OpenClaw
Avec Claude sous budget quotidien, nous avions besoin d’un modèle de secours. Mais voici ce que la plupart des gens ne réalisent pas : le choix ne se fait pas entre Claude, GPT et Gemini. Ce sont tous des modèles premium avec des prix premium. Quand vous faites tourner un agent IA en permanence via OpenRouter, les coûts de tokens s’accumulent rapidement.
Le vrai problème de coût
Soyons honnêtes sur les prix. Des modèles comme GPT-4o, Gemini 2.5 Pro et Claude via API facturent tous des frais par token significatifs. Nous ne les avons pas sérieusement évalués comme options de secours parce que tout l’intérêt du Smart Model Manager est l’optimisation des coûts. Payer 10 à 15 $ par million de tokens pour un modèle de secours va à l’encontre du but recherché.
Notre configuration fonctionne parce que nous équilibrons deux stratégies :
- Abonnement Claude Max — Coût mensuel fixe, qualité premium, mais avec des rate limits
- Kimi K2.5 via OpenRouter — Tokens API ultra-économiques pour l’utilisation excédentaire
C’est l’insight clé : vous n’avez pas besoin de deux modèles chers. Vous avez besoin d’un excellent modèle sur abonnement et d’un modèle économique pour le reste.
Pourquoi Kimi K2.5 nous a bluffés
Nous avons choisi Kimi K2.5 de Moonshot AI, et honnêtement, il a dépassé toutes nos attentes :
- Vraiment intelligent — Il gère des conversations multi-tours complexes, comprend le contexte nuancé et raisonne efficacement
- Excellent pour les tâches d’agent — Contrairement à certains modèles moins chers qui s’effondrent avec l’utilisation d’outils et les sorties structurées, Kimi K2.5 gère les workflows d’agent OpenClaw sans problème
- Incroyablement économique — À ~0,90 $ par million de tokens, c’est une fraction de ce que n’importe quel modèle premium coûte
La première fois que nous avons basculé vers Kimi pendant un événement de rate limit, nous nous attendions à une baisse de qualité. À la place, l’agent a continué à fonctionner normalement. Notre réaction réelle : “Oh mon dieu ça marche et il est intelligent.”
Les chiffres qui comptent
| Modèle | Coût (par 1M tokens) | Viable comme secours permanent ? |
|---|---|---|
| Claude Opus 4.5 (API) | ~15,00 $ | Non — trop cher |
| GPT-4o (API) | ~5,00 $ | Non — encore trop cher |
| Gemini 2.5 Pro (API) | ~3,50 $ | Non — s’accumule vite |
| Claude Sonnet 4.5 (API) | ~3,00 $ | Non — utilisez l’abonnement Max |
| Kimi K2.5 | ~0,90 $ | Oui — parfait pour l’excédent |
En pratique, lors d’une journée chargée où le budget de 3h30 de Claude s’épuise et Kimi gère les 4 à 6 heures restantes, nous dépensons environ 5 à 10 $ en tokens Kimi. C’est tout. Comparez ça à n’importe quel autre modèle via API pour la même durée et vous en seriez à 30–50 $+.
Nos coûts quotidiens réels
En faisant tourner OpenClaw en production avec cette configuration, nos dépenses réelles ressemblent à ça :
- Abonnement Claude Max : Frais mensuels fixes (couvre 3h30/jour de qualité premium)
- Kimi K2.5 excédentaire : ~5–10 $/jour les jours chargés, 0 $ les jours légers
- Budget Kimi mensuel : Environ 150–300 $ selon l’intensité d’utilisation
C’est le coût de faire tourner un agent IA 24h/24 qui gère WhatsApp, Telegram, la gestion des tâches et la coordination d’équipe. Pour un outil professionnel aussi puissant, c’est remarquablement abordable.
Une note sur la confidentialité
Kimi est développé par Moonshot AI, une entreprise chinoise. Bien que les clés API restent locales (OpenRouter gère le routage), vos prompts et contenus sont traités par les serveurs de Moonshot. Pour les charges de travail sensibles, tenez-en compte dans votre modèle de menaces. Pour nos tâches d’automatisation professionnelle générales, le compromis en vaut la peine.
Guide d’installation complet
Étape 1 : Créer le répertoire d’état
mkdir -p ~/.openclaw/logsÉtape 2 : Créer le script daemon principal
Sauvegardez comme ~/clawd/scripts/smart-model-manager.command :
#!/bin/bash
# Smart Model Manager : Gestion proactive du budget Claude pour OpenClaw
DAILY_BUDGET_SECONDS=$((3 * 3600 + 30 * 60))
MARGIN_SECONDS=$((10 * 60))
EFFECTIVE_BUDGET=$((DAILY_BUDGET_SECONDS - MARGIN_SECONDS))
CHECK_INTERVAL=60
STATE_FILE="$HOME/.openclaw/claude-usage-state.json"
LOG_FILE="$HOME/.openclaw/logs/model-manager.log"
WHATSAPP_SELF="+VOTRE_NUMERO_ICI"
mkdir -p "$HOME/.openclaw/logs"
log() {
echo "$(date '+%Y-%m-%d %H:%M:%S'): $1" >> "$LOG_FILE"
}
notify_whatsapp() {
openclaw message send --channel whatsapp -t "$WHATSAPP_SELF" -m "$1" 2>/dev/null
}
get_current_model() {
grep '"primary"' ~/.openclaw/openclaw.json | sed 's/.*: "\([^"]*\)".*/\1/'
}
switch_to_kimi() {
openclaw config set agents.defaults.model.primary "openrouter/moonshotai/kimi-k2.5"
openclaw gateway restart
notify_whatsapp "Basculé vers Kimi K2.5 (Budget Claude atteint)"
}
switch_to_claude() {
openclaw config set agents.defaults.model.primary "anthropic/claude-sonnet-4-5"
openclaw gateway restart
notify_whatsapp "Nouveau jour ! Basculé vers Claude Sonnet (budget 3h30 disponible)"
}
init_state() {
echo "{\"date\": \"$(date '+%Y-%m-%d')\", \"claude_seconds\": 0, \"budget_exhausted\": false}" > "$STATE_FILE"
}
# Boucle principale
while true; do
TODAY=$(date '+%Y-%m-%d')
STATE=$(cat "$STATE_FILE" 2>/dev/null || echo '{}')
STATE_DATE=$(echo "$STATE" | python3 -c "import sys,json; print(json.load(sys.stdin).get('date',''))")
CLAUDE_SECONDS=$(echo "$STATE" | python3 -c "import sys,json; print(json.load(sys.stdin).get('claude_seconds',0))")
# Nouveau jour ? Réinitialiser le budget et rebasculer vers Claude
if [[ "$STATE_DATE" != "$TODAY" ]]; then
init_state
CLAUDE_SECONDS=0
CURRENT_MODEL=$(get_current_model)
[[ "$CURRENT_MODEL" == *"openrouter"* ]] && switch_to_claude
fi
CURRENT_MODEL=$(get_current_model)
# Suivre le temps d'utilisation de Claude
if [[ "$CURRENT_MODEL" == *"anthropic"* ]]; then
CLAUDE_SECONDS=$((CLAUDE_SECONDS + CHECK_INTERVAL))
if [[ "$CLAUDE_SECONDS" -ge "$EFFECTIVE_BUDGET" ]]; then
echo "{\"date\": \"$TODAY\", \"claude_seconds\": $CLAUDE_SECONDS, \"budget_exhausted\": true}" > "$STATE_FILE"
switch_to_kimi
else
echo "{\"date\": \"$TODAY\", \"claude_seconds\": $CLAUDE_SECONDS, \"budget_exhausted\": false}" > "$STATE_FILE"
fi
fi
sleep $CHECK_INTERVAL
doneÉtape 3 : Créer le script de contrôle
Sauvegardez comme ~/clawd/scripts/model-manager.command :
#!/bin/bash
PLIST="$HOME/Library/LaunchAgents/com.perelbot.model-manager.plist"
STATE_FILE="$HOME/.openclaw/claude-usage-state.json"
case "${1:-status}" in
start)
launchctl bootstrap gui/$UID "$PLIST" 2>/dev/null
echo "Model Manager démarré"
;;
stop)
launchctl bootout gui/$UID/com.perelbot.model-manager 2>/dev/null
echo "Model Manager arrêté"
;;
restart)
$0 stop; sleep 1; $0 start
;;
status)
echo "=== Statut Smart Model Manager ==="
launchctl list | grep -q "com.perelbot.model-manager" && echo "Service : EN COURS" || echo "Service : ARRÊTÉ"
[[ -f "$STATE_FILE" ]] && python3 -c "
import json
with open('$STATE_FILE') as f: s = json.load(f)
secs = s['claude_seconds']
print(f'Claude utilisé aujourd\'hui : {secs//3600}h{(secs%3600)//60:02d}m')
print(f'Budget épuisé : {s[\"budget_exhausted\"]}')"
;;
esacNote : Ce guide utilise le LaunchAgent macOS. Pour les serveurs Linux, vous pouvez adapter ceci en service systemd ou en approche basée sur cron.
Étape 4 : Rendre exécutable et démarrer
chmod +x ~/clawd/scripts/smart-model-manager.command
chmod +x ~/clawd/scripts/model-manager.command
~/clawd/scripts/model-manager.command startSurveiller votre utilisation des tokens OpenClaw
Vérifiez votre statut à tout moment :
~/clawd/scripts/model-manager.command statusSortie :
=== Statut Smart Model Manager ===
Service : EN COURS
Claude utilisé aujourd'hui : 1h45m
Budget épuisé : FalseAnalyse des coûts : Ce que nous dépensons réellement
Voici ce que coûte réellement un agent IA 24h/24 avec notre configuration :
| Scénario | Coût Claude | Coût Kimi K2.5 | Total quotidien |
|---|---|---|---|
| Journée légère (3h Claude seul) | 0 $ (plan Max) | 0 $ | 0 $ |
| Journée normale (3h30 Claude + 3h Kimi) | 0 $ (plan Max) | ~3–5 $ | ~3–5 $ |
| Journée chargée (3h30 Claude + 6h Kimi) | 0 $ (plan Max) | ~7–10 $ | ~7–10 $ |
Notre répartition mensuelle type :
- Abonnement Claude Max : Frais fixes mensuels
- Kimi K2.5 via OpenRouter : ~150–300 $/mois
Ce que ça coûterait sans ce système :
- API Claude pure aux tarifs Opus pour le même usage : 1 500 $+/mois
- API GPT-4o pure : 800 $+/mois
- API Gemini Pro pure : 600 $+/mois
Le Smart Model Manager nous fait économiser environ 80–90% par rapport à un modèle premium utilisé uniquement via API. Claude Max nous donne la meilleure qualité quand on en a le plus besoin, et Kimi K2.5 assure le reste — à un prix qui rend l’exploitation d’un agent IA 24h/24 réellement viable.
5 leçons que nous avons apprises sur la gestion des tokens IA
1. Les pannes silencieuses sont les pires pannes
Quand votre agent IA casse sans vous le dire, vous perdez des heures à débuguer le mauvais problème. Construisez de l’observabilité dans tout. Les notifications WhatsApp ne sont pas optionnelles — c’est de l’infrastructure essentielle.
2. Le proactif bat toujours le réactif
Répondre aux erreurs après qu’elles surviennent signifie que vos utilisateurs ont déjà eu une mauvaise expérience. Prévenir les erreurs avant qu’elles ne surviennent signifie un service sans accroc. La marge de sécurité de 10 minutes n’est pas de la paranoïa — c’est une assurance.
3. Kimi K2.5 change la donne pour les opérations IA soucieuses des coûts
Nous pensions que Claude était irremplaçable. Kimi K2.5 nous a prouvé le contraire. À ~0,90 $ par million de tokens, il gère la grande majorité des tâches quotidiennes d’agent — conversations, gestion de tâches, coordination d’équipe — sans sourciller. Oubliez la comparaison entre modèles premium. Le vrai jeu consiste à associer un modèle premium sur abonnement avec un modèle API ultra-économique. C’est là que la magie opère.
4. Automatisez tout — surtout la gestion des modèles
Le basculement manuel entre modèles est fastidieux et source d’erreurs. Un daemon qui tourne 24h/24, se réinitialise à minuit et gère tous les cas limites automatiquement signifie que vous vous concentrez sur le vrai travail au lieu de surveiller votre infrastructure IA.
5. Connaissez vos rate limits (et fixez-en de plus stricts)
Les rate limits d’Anthropic sont mal documentés et appliqués de manière inconsistante. En imposant nos propres limites plus strictes, nous n’avons jamais à deviner si nous sommes sur le point de heurter un mur. Les contraintes auto-imposées vous donnent le contrôle.
Les résultats : Avant vs. Après

Après l’implémentation du Smart Model Manager :
- Zéro erreur de rate limit en production depuis le déploiement
- Visibilité totale sur l’utilisation de Claude via les notifications WhatsApp
- Coûts prévisibles avec Kimi K2.5 qui gère le trafic excédentaire
- Tranquillité d’esprit en sachant que le système se gère lui-même 24h/24
L’agent est passé de “subitement bête” à “toujours fiable.” C’est la différence entre éteindre des incendies de manière réactive et faire de l’ingénierie proactive.
Conclusion : N’attendez plus que les rate limits frappent
Si vous faites tourner OpenClaw ou n’importe quel agent IA avec des limites d’utilisation, la leçon est simple : n’attendez pas les pannes — construisez les garde-fous avant d’en avoir besoin.
Notre Smart Model Manager vous donne :
- Prévisibilité — Sachez exactement combien de temps Claude vous avez chaque jour
- Zéro erreur de rate limit — Basculez de modèle avant d’atteindre les limites
- Optimisation des coûts — Utilisez des modèles moins chers pour le trafic excédentaire
- Visibilité totale — Les notifications WhatsApp en temps réel vous tiennent informé
- Automatisation totale — Configurez une fois et oubliez
Le système tourne silencieusement en arrière-plan, gérant votre budget IA comme un bon conseiller financier — maximisant la valeur tout en évitant les erreurs coûteuses.
Vous voulez mettre en place l’automatisation IA pour votre entreprise ? Nous faisons tourner OpenClaw en production depuis des semaines et avons appris à nos dépens ce qui fonctionne et ce qui ne fonctionne pas. Réservez une session stratégie gratuite et parlons de comment les agents IA peuvent transformer votre workflow. Découvrez aussi notre service Assistant IA propulsé par OpenClaw.
Construit avec OpenClaw 2026.2.6, Claude Sonnet 4.5 et Kimi K2.5 via OpenRouter. Ce qui a commencé comme un après-midi de frustration à débuguer est devenu une solution permanente qui gère notre infrastructure IA 24h/24.
Prêt à transformer votre présence en ligne ?
Discutons de la manière dont nous pouvons aider votre entreprise à se développer grâce à un site web performant
Roy Perelgut
Fondateur & Stratège Digital
Fort de 22 ans d'expérience en technologies de l'information, Roy a fondé Perel Web Studio avec une conviction : la passion est ce qui distingue une bonne agence web d'une mauvaise.
Passionné par la création de solutions digitales qui génèrent de vrais résultats, il dirige une équipe de 6 personnes depuis Bruxelles, en collaboration avec des développeurs talentueux au Sri Lanka, livrant des projets qui atteignent le classement n°1 sur Google et multiplient les leads.
Son approche combine excellence technique, stratégie SEO pointue et un engagement sans compromis envers la réussite de chaque client.













