Le stack d'audit SEO & GEO : 13 skills Claude Code pour auditer un site sans hallucinations
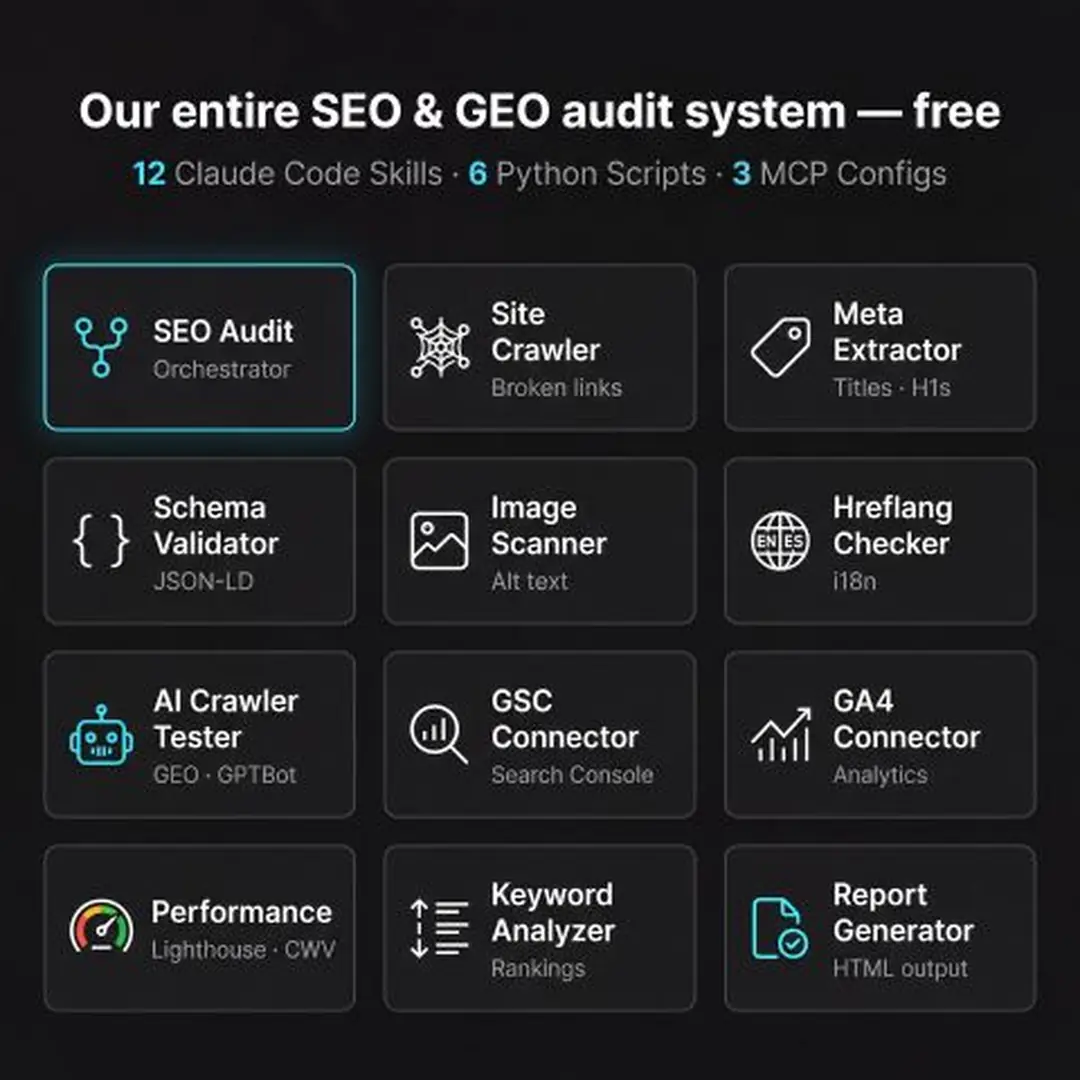
Les 13 skills Claude Code, 6 crawlers Python et 3 configs MCP que nous utilisons en production pour des audits SEO & GEO agentiques. Prêt à l'emploi, entièrement documenté, téléchargement gratuit.

Fort de 22 ans d'expérience en IT, Roy dirige Perel Web Studio avec une passion inébranlable pour créer des solutions digitales qui génèrent de vrais résultats. La seule différence entre une bonne et une mauvaise agence web ? La passion.
Nous avons reconstruit tout le process d’audit SEO de notre agence à Bruxelles sur Claude Code et le Model Context Protocol. Ce qui prenait une semaine de travail manuel dans Screaming Frog, Lighthouse, Google Search Console et une douzaine de feuilles de calcul tourne maintenant en une seule commande agentique — et le livrable est suffisamment solide pour être envoyé à un client payant.
Cet article documente le stack complet : 13 skills Claude Code, 6 crawlers Python et 3 configurations de serveurs MCP. Chaque fichier est ouvert et téléchargeable ci-dessous — pas besoin d’e-mail pour lire cette page, uniquement si vous voulez récupérer le code sur votre poste.
Le plus dur n’a pas été d’écrire les skills. Ç’a été de trouver quels serveurs MCP fonctionnaient vraiment, quelles APIs renvoyaient des données fiables, et quelles approches n’hallucinaient pas. Nous avons testé des dizaines de configurations sur plusieurs mois avant d’arrêter ce stack.
Si vous préférez qu’on l’exécute sur votre site — rapport complet, constats priorisés, walkthrough de 30 minutes — nous le proposons en forfait fixe : audit IA agentique à 300 €, livré en 48 heures.
Pourquoi la plupart des « audits SEO IA » sont inutiles
Si vous avez cherché « audit SEO IA » récemment, vous connaissez le pattern : un outil gratuit qui demande à ChatGPT d’« auditer cette URL » et renvoie un rapport bien présenté. Le modèle n’a jamais crawlé votre site. Il a inventé votre vitesse de page, fabriqué des problèmes techniques, deviné des positions de mots-clés. Le résultat est un texte bien rédigé mais en grande partie faux.
Notre règle, apprise à la dure :
Les scripts Python collectent les faits. L’IA n’écrit que la prose.
Chaque chiffre qui finit dans un audit Perel Web Studio peut être retracé jusqu’à un fichier CSV ou JSON produit par un script qui a réellement requêté l’URL, parsé le HTML ou appelé une vraie API. Le travail du LLM se limite à lire ces fichiers, à prioriser les constats par impact business, et à rédiger la synthèse exécutive. C’est la seule façon de rendre un audit IA défendable.
C’est cette séparation que décrit le reste de l’article.
Ce que l’audit agentique couvre
Chacun des éléments suivants tourne en parallèle dans un skill Claude Code séparé :
- Crawl du site & liens cassés — chaque URL du sitemap, statut HTTP de chaque lien interne
- Balises meta & contenu — title, description, H1/H2, nombre de mots, canonical, balises OG
- Schémas / JSON-LD — chaque bloc de données structurées extrait et classé
- Couverture des alt d’images — par page et globalement
- Vérification hreflang — chaque URL alternative testée pour un 200 effectif
- Accès des crawlers IA — GPTBot, ClaudeBot, PerplexityBot, OAI-SearchBot, Google-Extended, Bingbot…
- Données Google Search Console live — clics, impressions, top requêtes, top pages, répartition par appareil
- Données Google Analytics 4 live — canaux, pages de destination, appareils
- Core Web Vitals via Chrome DevTools MCP — LCP, INP, CLS, avec l’élément bloquant réel identifié
- Suivi de positions — importé depuis les exports CSV (SEMrush, Mangools, Ahrefs)
- PageSpeed Insights — données terrain CrUX, données lab Lighthouse
L’orchestrateur lit ensuite tous ces fichiers et compile un rapport unique priorisé.
L’architecture en un schéma
┌────────────────────────────────┐
│ /seo-audit (orchestrateur) │
└────────────┬───────────────────┘
│ tourne tout en parallèle
┌───────────────┴──────────────────────┐
▼ ▼
┌─────────────────────┐ ┌──────────────────────┐
│ Crawlers Python │ │ Sources MCP │
│ (vérif. machine) │ │ (APIs live) │
├─────────────────────┤ ├──────────────────────┤
│ crawl.py │ │ Google Search │
│ meta.py │ │ Console │
│ schema.py │ │ Google Analytics 4 │
│ images.py │ │ Chrome DevTools │
│ hreflang.py │ └──────────────────────┘
│ ai_crawlers.py │
└──────────┬──────────┘
│ sort CSV + JSON
▼
┌──────────────────────────────────────────────────────────┐
│ Claude lit les fichiers et rédige le rapport final │
│ (chaque affirmation doit citer un fichier source) │
└──────────────────────────────────────────────────────────┘Les 13 skills, un par un
Chaque skill est un fichier SKILL.md autonome. Vous les déposez dans ~/.claude/skills/ et Claude Code les détecte automatiquement. Le skill orchestrateur (seo-audit) coordonne les autres.
1. seo-audit — l’orchestrateur
Le point d’entrée. Une seule commande lance les 6 crawlers Python en parallèle, récupère les analytics live de GSC et GA4, exécute l’audit de performance, puis compile le rapport final.
/seo-audit votredomaine.com https://votredomaine.com/sitemap.xmlIl applique les pondérations de scoring que nous utilisons sur tous nos audits SEO clients : 22 % SEO technique, 23 % qualité du contenu, 20 % on-page, 10 % schémas, 10 % performance, 10 % AI search readiness, 5 % images.
2. seo-audit-crawl — crawler de site
Parcourt le sitemap, vérifie le statut HTTP de chaque URL, suit chaque lien interne, et écrit un CSV des liens brisés avec la page où ils ont été trouvés. Aucune exécution JavaScript — la même vue qu’un moteur de recherche qui ne rend pas le JS.
Sortie :
{domain}_crawl.csv— chaque URL avec son code de statut{domain}_broken_links.csv— liens brisés + page d’origine
3. seo-audit-meta — extracteur de balises meta
Extrait le title, la meta description, le H1, tous les H2, le nombre de mots, l’URL canonique et les balises Open Graph de chaque page. Détecte automatiquement :
<title>manquant ou vide- Title trop court (moins de 30 caractères) ou trop long (plus de 60 caractères)
- Titles dupliqués entre pages
- Meta description manquante
- Pages avec plusieurs H1
- Pages avec moins de 300 mots
4. seo-audit-schema — extracteur de JSON-LD
Récupère chaque bloc <script type="application/ld+json"> sur chaque page, le valide et classe le type de schéma. Les plus courants : Organization, Product, BlogPosting, BreadcrumbList, FAQPage, Article, LocalBusiness.
Sortie : un comptage par page, un total par type, et la liste des erreurs de parsing. Les manques de schéma se traduisent directement en opportunités de rich results manquées.
5. seo-audit-images — audit des alt
Parcourt chaque page à la recherche des balises <img> et classifie chacune : alt valable, alt vide, alt manquant. Exclut automatiquement les pixels de tracking (1×1 px), les icônes SVG inline et les data: URIs — ces éléments n’ont pas besoin d’alt.
Sortie : pourcentage de couverture par page et statistique globale. On a constaté que des sites pensent être à 95 % de couverture et tombent à 60 % une fois le bruit filtré.
6. seo-audit-hreflang — vérification multilingue
Celui-là est crucial pour tout site multilingue. Pour chaque page, il extrait chaque balise <link rel="alternate" hreflang="…">, puis récupère réellement chaque URL alternative pour vérifier qu’elle renvoie 200. Trois bugs récurrents détectés :
- URLs alternatives cassées (la page ciblée n’existe plus)
x-defaultmanquant- Boucles de redirection entre versions linguistiques
7. seo-audit-ai-crawlers — test d’accessibilité GEO
Celui qui attire le plus d’attention depuis que l’AI search est devenue réelle. Teste si chacun des crawlers suivants peut accéder à votre site :
GPTBot · ClaudeBot · PerplexityBot · OAI-SearchBot · Google-Extended · Googlebot · Bingbot · applebot · cohere-ai
Vérifie également le robots.txt pour les directives qui les bloquent, et la présence du fichier /llms.txt. La sortie indique précisément quels assistants IA peuvent voir votre contenu — et donc lesquels peuvent vous citer dans leurs réponses.
8. seo-audit-gsc — Google Search Console (live)
Se connecte via le serveur MCP GSC et récupère :
- Clics totaux, impressions, CTR, position moyenne
- Top 50 requêtes (avec delta vs. période précédente)
- Top 50 pages
- Répartition par appareil (mobile / desktop / tablette)
- Répartition par pays (top 20)
- Tendances quotidiennes
Pas d’export CSV, pas de connexion à l’interface GSC. Les données sont en direct.
9. seo-audit-ga — Google Analytics 4 (live)
Se connecte via le serveur MCP Analytics et récupère :
- Sessions, utilisateurs, pages vues, taux de rebond par canal
- Top 20 pages de destination avec métriques d’engagement
- Répartition par catégorie d’appareil
- Géographie (top 20 pays)
Corréler les requêtes GSC avec l’engagement GA4 sur les pages de destination, c’est là que se trouvent la plupart des insights actionnables. Les deux scripts sont conçus pour être lus ensemble.
10. seo-audit-performance — Lighthouse + Chrome DevTools
Utilise le serveur MCP Chrome DevTools pour exécuter un audit Lighthouse complet et un trace de performance sur vos templates clés. Ne se contente pas du score — identifie l’élément LCP réel, la plus longue interaction INP, et quel script tiers en est responsable.
Seuils déclenchés : LCP > 2500 ms, INP > 200 ms, CLS > 0,1.
11. seo-audit-keywords — suivi de positions
Importe des CSVs de positions depuis Mangools, SEMrush, Ahrefs ou SEOcrawl et identifie :
- Mots-clés en positions 4–10 (un pas vers le top 3)
- Mots-clés en positions 11–20 (un pas vers la page 1)
- Mots-clés en position 101+ avec un volume élevé (le seau « vous devriez ranker mais vous ne rankez pas »)
- Cas où la mauvaise page ranke pour un mot-clé
12. seo-audit-pagespeed — API PageSpeed Insights
Récupère les données terrain du Chrome User Experience Report (CrUX) pour vos top URLs — pour voir les Core Web Vitals réels de vos visiteurs, pas seulement les chiffres lab. API Google gratuite, pas de MCP nécessaire.
13. seo-audit-content — passe qualité de contenu
Le seul skill qui utilise le LLM pour évaluer, mais cantonné à votre propre contenu : lit le texte extrait page par page, le note sur le cadre E-E-A-T (Expérience, Expertise, Autorité, Trustworthiness) plus la « citation-readiness » IA, et signale les pages thin.
C’est le dernier skill exécuté — et même ici, chaque score doit citer des phrases précises de la page.
Récupérer le stack complet
Les 13 fichiers SKILL.md, les 6 scripts Python, les 3 configurations MCP et un README de mise en place — le tout dans un zip. Laissez votre e-mail + nom de société pour recevoir le lien par e-mail, ou téléchargez tout instantanément ci-dessous.
Téléchargez le stack complet
13 skills · 6 scripts Python · 3 configs MCP. Prêts à l’emploi.
Les téléchargements sont débloqués ci-dessous. Un e-mail récapitulatif vient d’être envoyé à l’adresse fournie.
Téléchargements
Tout télécharger (zip)Ou par fichier individuel
Vous préférez qu’on l’exécute pour vous ?
On exécute exactement ce stack sur n’importe quel site web pour 300 € — rapport complet livré en 48 heures + walkthrough de 30 minutes inclus.
Les 6 scripts Python en 10 lignes chacun
Chacun des skills techniques s’appuie sur un petit script Python. Nous les avons volontairement gardés courts (~200 lignes chacun, librairie standard uniquement — pas de requests, pas de BeautifulSoup) pour qu’ils soient faciles à lire et à auditer.
| Script | Rôle | Sortie |
|---|---|---|
crawl.py | Crawler chaque URL du sitemap, suivre les liens internes, vérifier les statuts HTTP | crawl.csv, broken_links.csv |
meta.py | Extraire title, description, H1/H2, nombre de mots, canonical, balises OG | meta.csv, meta_issues.csv |
schema.py | Récupérer chaque bloc JSON-LD, classer le type, compter par page | schema.csv, schema_summary.json |
images.py | Statut alt par image, en filtrant pixels de tracking et icônes SVG | images.csv, images_stats.json |
hreflang.py | Vérifier que chaque alternative hreflang renvoie 200 | hreflang.csv, hreflang_summary.json |
ai_crawlers.py | Tester 9 user-agents de crawlers IA/recherche sur la page d’accueil | ai_crawlers.csv, ai_crawlers_summary.json |
Le reste — format de fichier, gestion des erreurs, parallélisme — est dans le bundle.
Les 3 configurations de serveurs MCP
// ~/.claude/settings.json (extrait)
{
"mcpServers": {
"gsc": {
"command": "npx",
"args": ["-y", "gsc-mcp-server"]
},
"analytics-mcp": {
"command": "npx",
"args": ["-y", "analytics-mcp-server"]
},
"chrome-devtools": {
"command": "npx",
"args": ["-y", "chrome-devtools-mcp"]
}
}
}L’authentification GSC et Analytics se fait une seule fois via OAuth et les tokens sont rafraîchis automatiquement. Le premier audit est le seul qui demande une authentification. Le bundle inclut les étapes OAuth exactes pour chaque — y compris les pièges que nous avons rencontrés.
Lancer un audit complet
# dans n'importe quel répertoire, avec Claude Code installé et les skills déposées :
mkdir -p ./reports/votredomaine
cd ./reports/votredomaine
claude
> /seo-audit votredomaine.com https://votredomaine.com/sitemap.xmlL’orchestrateur exécute les 11 audits en parallèle. Sur un site de 200 pages, cela prend 6 à 10 minutes de bout en bout. Le rapport final est écrit dans ./reports/votredomaine/REPORT.md.
Pour les portefeuilles multi-sites, vous pouvez passer plusieurs domaines en un appel :
> /seo-audit site1.com sitemap1.xml site2.com sitemap2.xmlÀ quoi ressemble le rapport final
La sortie est un unique rapport Markdown avec :
- Synthèse exécutive — trois phrases, score (sur 100), trois priorités principales
- Scorecard — les sept scores par catégorie avec leurs pondérations
- Problèmes critiques — chacun avec : ce qu’on a trouvé, où, pourquoi c’est important, le correctif précis
- Gains rapides — corrections qui prennent moins d’une heure
- Recommandations stratégiques — chantiers plus longs, classés par impact business
- Annexes — liens vers chaque CSV/JSON brut produit par les crawlers
Chaque affirmation cite un fichier source. Si le rapport dit « 23 pages ont une meta description manquante », vous pouvez ouvrir meta_issues.csv, filtrer sur le problème, et voir les 23 URLs.
Vous voulez plutôt qu’on l’exécute sur votre site ?
Installer Claude Code, les serveurs MCP, les tokens OAuth et les 13 skills n’est pas une affaire de 10 minutes. Si vous préférez qu’on exécute le stack sur votre site et qu’on vous remette le rapport, c’est exactement le service Audit IA Agentique à 300 €.
- 300 €, forfait fixe — pas de dérive de scope, pas de surcoût dans le rapport
- Livraison en 48 heures à partir de la réservation
- Rapport PDF + HTML + walkthrough de 30 minutes
- Le coût est déduit du devis si vous nous confiez ensuite l’implémentation
C’est le stack documenté dans cet article, exécuté sur votre domaine, avec la revue humaine par-dessus.
Pourquoi on l’a publié en open source
Trois raisons.
1. C’est la bonne chose à faire. Ce n’est pas un secret commercial. C’est l’application rigoureuse de principes SEO bien connus, automatisée. Si quelqu’un avec un petit site télécharge le bundle et exécute son propre audit, c’est une victoire — et un site de moins pollué par des conseils SEO IA hallucinés.
2. La curation du stack est la valeur, pas son exécution. Le plus dur n’a pas été d’écrire les scripts. Ç’a été de trouver quels serveurs MCP ne cassent pas, quelles APIs renvoient des données fiables, et quelles structures de prompts gardent le LLM honnête. Ce travail — des mois de tests — est intégré au bundle. Toute personne qui le télécharge évite ce calvaire.
3. Cela génère le bon type d’inbound. Les fondateurs et marketeurs in-house qui lisent cet article et téléchargent le bundle sont déjà à moitié qualifiés pour notre agence SEO à Bruxelles. Si le stack leur plaît, ils reviendront quand ils auront besoin d’un partenaire pour l’implémentation.
Donc : téléchargez-le, utilisez-le, partagez-le. Et si vous voulez qu’il soit exécuté sur votre site par les gens qui l’ont construit, on n’est qu’à un e-mail.
Prêt à transformer votre présence en ligne ?
Discutons de la manière dont nous pouvons aider votre entreprise à se développer grâce à un site web performant
Roy Perelgut
Fondateur & Stratège Digital
Fort de 22 ans d'expérience en technologies de l'information, Roy a fondé Perel Web Studio avec une conviction : la passion est ce qui distingue une bonne agence web d'une mauvaise.
Passionné par la création de solutions digitales qui génèrent de vrais résultats, il dirige une équipe de 6 personnes depuis Bruxelles, en collaboration avec des développeurs talentueux au Sri Lanka, livrant des projets qui atteignent le classement n°1 sur Google et multiplient les leads.
Son approche combine excellence technique, stratégie SEO pointue et un engagement sans compromis envers la réussite de chaque client.













